Redis is one of the most popular in-memory data stores today — fast, simple, and widely adopted.
But when it comes to deploying Redis in production, the question is no longer “How do I run Redis?” — it’s “Which mode should I run it in?”
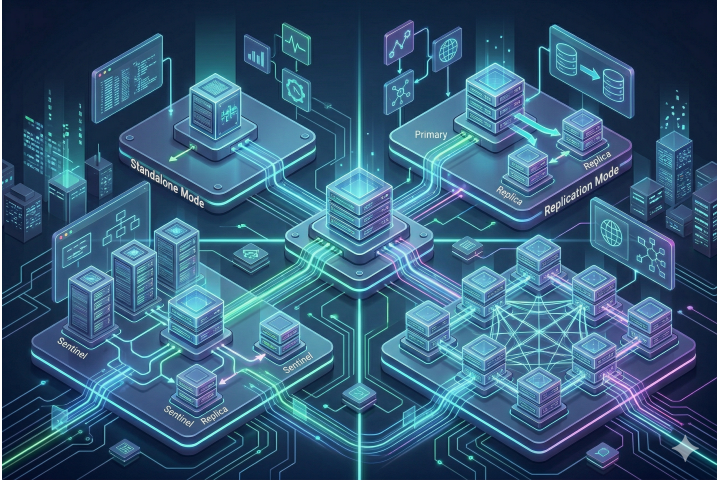
In this guide, we’ll explore Redis’s four main operation modes:
- Standalone
- Replication (Master–Slave)
- Sentinel
- Cluster
We’ll discuss what each mode does, when it’s useful, and when you should consider moving to the next level.
1. Redis Standalone
What It Is
The simplest form of Redis — a single redis-server instance running on one machine.
All reads and writes happen on the same node. There’s no replication, no sharding, and no automatic failover.
When It Makes Sense
- Development or testing environments
- Small-scale production use, where Redis is only a cache and data loss is tolerable
- Single-node setups where simplicity is more important than availability
Pros ✅
- Easiest to set up and maintain
- Fastest in terms of raw latency
- Minimal configuration and cost
Cons ❌
- Single point of failure
- No fault tolerance
- Limited to one machine’s memory and CPU
👉 Rule of thumb: Start with standalone only if you can afford to lose the cache or tolerate short downtimes.
2. Redis Replication (Master–Slave)
What It Is
Replication means having one master and one or more slaves.
Slaves continuously copy data from the master asynchronously.
If the master fails, you still have the data — but switching roles is manual.
replicaof redis-master 6379
When It Makes Sense
- When you want read scalability — distribute reads across multiple replicas.
- When you want basic redundancy — data isn’t lost even if the master dies.
- When manual failover is acceptable.
Pros ✅
- Adds redundancy without major complexity
- Easy to scale for read-heavy workloads
- Low replication overhead
Cons ❌
- No automatic failover
- Writes still go to a single master
- Failover requires manual intervention
👉 Tip: Replication is the first step toward high availability — but it’s not HA by itself.
3. Redis Sentinel
What It Is
Redis Sentinel builds on top of replication to provide automatic failover and high availability (HA).
Sentinel nodes constantly monitor your master and slaves:
- If the master goes down, Sentinels vote to promote one of the slaves as the new master.
- They notify the clients automatically so the application can reconnect to the new master.
Typical Topology
Sentinel 1 ─┐
Sentinel 2 ─┤
Sentinel 3 ─┘
│
Redis Master ←→ Redis Slaves
When It Makes Sense
- Your Redis instance is critical to uptime (e.g., sessions, auth tokens, or caching layer for production).
- Your dataset fits in one machine’s memory, so sharding isn’t required.
- You want HA without manual intervention, but prefer to keep your data on a single logical Redis instance.
Pros ✅
- Automatic failover and monitoring
- HA with multiple replicas
- Simple to scale reads
Cons ❌
- Still a single master, so no horizontal scaling
- Setup requires at least three Sentinel processes for quorum
- Slight delay during failover
👉 Tip: Sentinel is ideal for small to medium production systems that need HA but don’t need to scale horizontally.
4. Redis Cluster
What It Is
Redis Cluster distributes your data across multiple nodes using hash slots (16,384 in total).
Each node is responsible for a portion of the keyspace — and each master can have replicas for HA.
So you get:
- Sharding (horizontal scaling)
- Replication (HA) in one system.
Typical Topology
Master A ←→ Replica A Master B ←→ Replica B Master C ←→ Replica C
When It Makes Sense
- Your dataset no longer fits into a single node’s memory
- You need massive throughput and low latency at scale
- You want both HA and horizontal scalability
Pros ✅
- True horizontal scaling
- Built-in HA with replicas
- Automatic failover
Cons ❌
- More complex setup and management
- Multi-key operations (like MGET, transactions, Lua scripts) only work within the same shard
- Client libraries must be Cluster-aware
👉 Tip: Use Cluster when Redis becomes your core data layer, not just a cache.
Summary Comparison
| Mode | HA | Sharding | Automatic Failover | Best For |
|---|---|---|---|---|
| Standalone | ❌ | ❌ | ❌ | Dev / small cache |
| Replication | ❌ (manual) | ❌ | ❌ | Read scalability |
| Sentinel | ✅ | ❌ | ✅ | HA for medium workloads |
| Cluster | ✅ | ✅ | ✅ | Large-scale, production workloads |
Choosing the Right Mode
You can think of these modes as an evolution path:
- Start simple: Standalone in dev or staging.
- Add replication: When you need read scalability or backups.
- Add Sentinel: When uptime and automatic recovery become important.
- Move to Cluster: When scaling horizontally or handling large datasets.
Standalone → Replication → Sentinel → Cluster
Each step adds resilience, scalability, and complexity.
Choose the smallest setup that meets your current reliability and performance needs — and evolve when necessary.
Final Thoughts
Redis gives you the flexibility to start small and grow big.
There’s no one-size-fits-all configuration — the right mode depends on:
- Your availability requirements
- Your data size
- Your team’s operational experience
If you’re just building your first production-ready Redis deployment, start with Sentinel.
If you already know Redis is mission-critical and will outgrow a single machine — go Cluster.